TPU와 GPU의 아키텍처 차이는 “범용성 vs 특화”에 있습니다. GPU는 그래픽스부터 시작해 다양한 병렬 계산에 강한 범용 병렬 프로세서이고, TPU는 행렬 곱(Matrix Multiplication)만 극도로 잘하는 ASIC입니다.
1. 핵심 아키텍처 비교
GPU는 범용 병렬 프로세서(GPGPU)로 설계되었습니다. 수천에서 수만 개에 이르는 CUDA Core와 Tensor Core를 주요 연산 유닛으로 사용하며, SIMT(Single Instruction Multiple Threads) 방식으로 수많은 스레드를 동시에 실행합니다. 이 때문에 그래픽스, 과학 계산, 다양한 AI 작업 등 유연성이 매우 높고 거의 모든 종류의 병렬 작업을 처리할 수 있다는 강점이 있습니다. 다만 행렬 연산을 할 때 메모리 이동 overhead가 상대적으로 많다는 단점이 있습니다.
반면 TPU는 ASIC(Application-Specific Integrated Circuit)으로, 행렬 곱 연산에 극도로 특화된 칩입니다. Systolic Array(대형 MXU: Matrix Multiply Unit)를 핵심 연산 유닛으로 사용하며, 데이터가 조립라인처럼 한 방향으로 흐르면서 자동으로 곱셈과 누산이 이루어지는 구조입니다. 이 덕분에 행렬 곱 throughput이 매우 높고 에너지 효율(Perf/Watt)이 뛰어나 대규모 Transformer 모델 학습·추론에서 특히 강력합니다. 대신 유연성이 부족하고, 주로 TensorFlow나 JAX 환경에 최적화되어 있다는 제한이 있습니다.
요약하면,
• GPU는 “만능 주방칼”처럼 다양한 작업에 두루 사용할 수 있는 범용 병렬 프로세서이고,
• TPU는 “행렬 곱만 미친 듯이 빠른 조립라인 로봇”처럼 한 가지 일(대규모 행렬 연산)에 극도로 최적화된 특화 칩입니다.

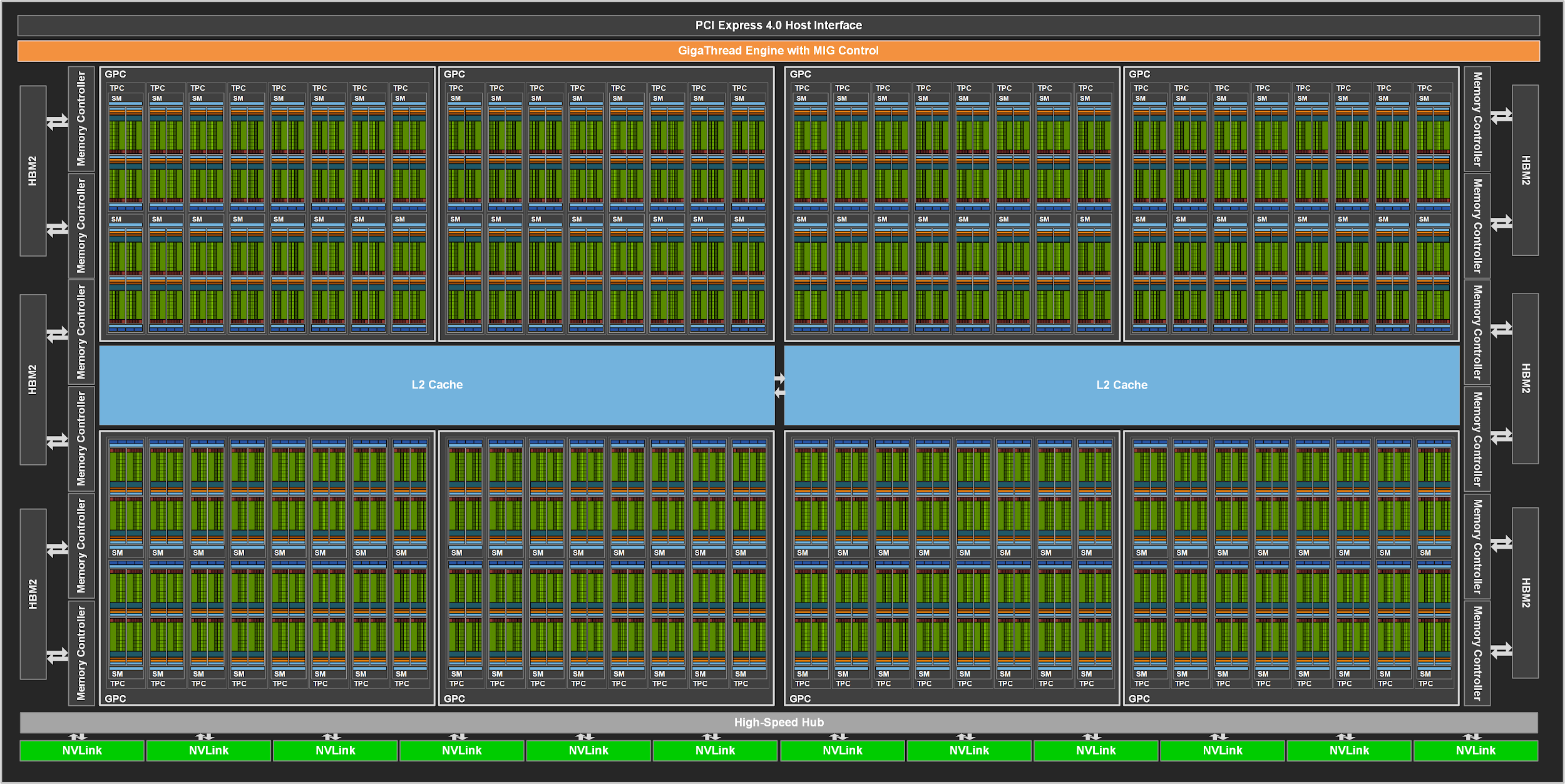
2. GPU 아키텍처 상세 (NVIDIA Hopper/Blackwell)
• Streaming Multiprocessor (SM) 단위로 구성: 각 SM 안에 수십~수백 CUDA Core + Tensor Core.
• Tensor Core: 작은 systolic array를 SM 안에 내장 (예: 4×4, 16×16 단위). GPU 전체는 수천 개의 이런 작은 유닛이 병렬로 동작.
• 데이터 이동이 많음 → 고대역폭 HBM 메모리와 복잡한 캐시 계층으로 보완.
• 장점: PyTorch, CUDA, 다양한 모델, 동적 그래프, 그래픽스/과학 계산 모두 가능.

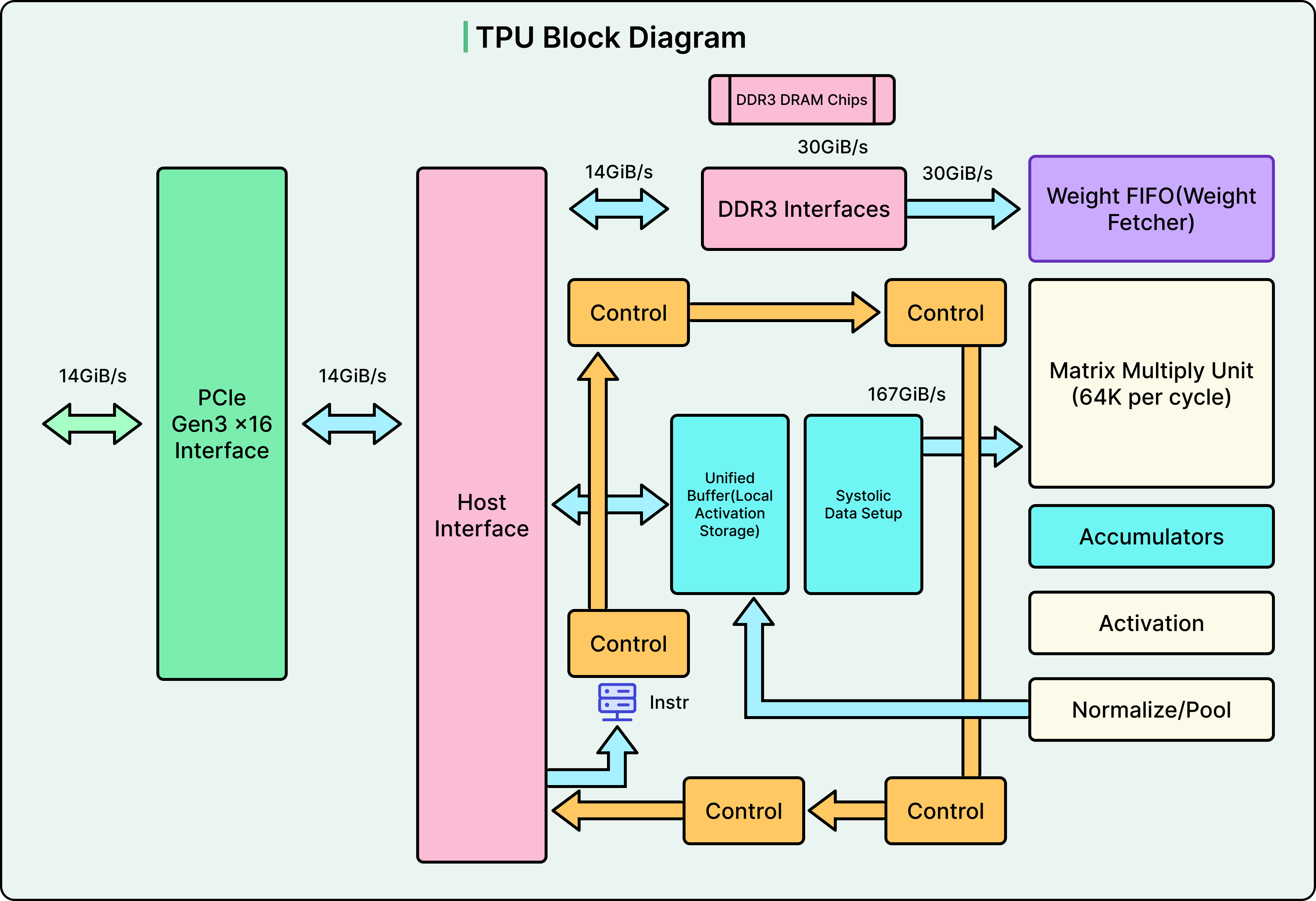
3. TPU 아키텍처 상세
• Systolic Array (MXU): 128×128 또는 256×256 규모의 거대한 2D 곱셈-누산기 배열.
◦ 데이터(Activation)와 가중치(Weight)가 배열을 따라 한 방향씩 흐르면서 자동으로 곱셈·누산.
◦ 메모리 접근 횟수를 극도로 줄임 (조립라인처럼 데이터가 한 번 들어가서 쭉 처리).
• Unified Buffer + Vector Unit + Scalar Unit으로 보완.
• SparseCore (최신 버전): embedding 테이블 같은 희소 연산 최적화.


4. 왜 TPU가 특정 작업에서 더 효율적인가?
• Systolic Array의 장점: GPU처럼 매번 데이터를 불러오고 보내는 overhead가 적음. 한 번 데이터가 들어가면 배열 안에서 리듬감 있게 처리 → 전력 대비 성능(Perf/Watt)이 높음.
• 대규모 배치(Batch) + 정형화된 Transformer 연산에서 특히 강력.
• Google Pod 규모(수천~만 개 TPU 연결)에서 interconnect(ICI, Optical Circuit Switch)로 초대형 클러스터를 효율적으로 만듦.
5. 언제 무엇을 써야 할까?
• GPU: 연구, 프로토타이핑, PyTorch 중심, 다양한 모델, 멀티 클라우드, 그래픽스/시뮬레이션 필요 시.
• TPU: Google Cloud에서 대규모 학습·추론, 비용·전력 효율 최우선, JAX/TensorFlow로 충분할 때.
결론: GPU는 “만능 주방 칼”이고, TPU는 “행렬 곱만 미친 듯이 빠른 조립라인 로봇”입니다. AI 모델 대부분이 행렬 곱 중심이라 TPU가 특정 상황에서 압도적이지만, 생태계·유연성에서는 GPU가 여전히 앞섭니다.
'반도체' 카테고리의 다른 글
| 한국 반도체 공급망 전략 심화 분석 (2026년 5월 기준) (0) | 2026.05.24 |
|---|---|
| 반도체 직무 소개 (0) | 2026.05.21 |
| CXL 동향 (0) | 2026.05.15 |
| HBF - HBM과 NAND 통합 기술 (0) | 2026.05.15 |
| 낸드 스케일링 이슈와 대안 모색 (0) | 2026.05.15 |